Author:360天眼实验室
由于杀软对商业壳比较敏感,并且商业壳检测,脱壳技术比较成熟,病毒作者一般不会去选择用商业的壳来保护自己的恶意代码,所以混淆壳成为了一个不错的选择.混淆壳可以有效对抗杀软,因为这种壳一般不存在通用的检测方法,并且很难去静态的脱壳,所以其恶意代码就不会被发现,从而使自己长时间的存在.对于恶意代码分析者来说,分析这种带混淆壳的样本往往会花费很大精力,甚至有时候会使分析变得不可能。本文主要几种常见的混淆手段,不涉及样本本身功能分析。
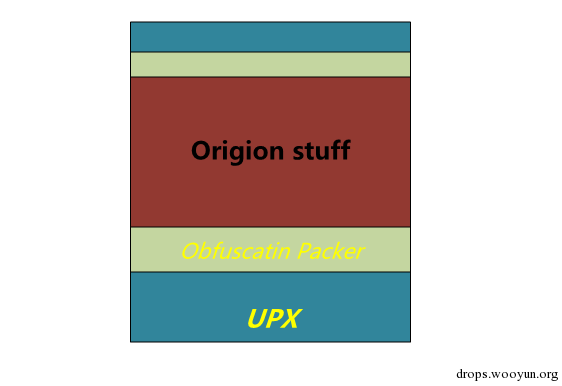
Citadel(md5: 767a861623802da72fd6c96ce3a33bff)是一个zeus的衍生版本,其较zeus更加的健壮,也更稳定。前一段时间发现了一个citadel 样本,较之普通的citadel稍微有一点特别,其整体的结构如下图:
图1 Citadel样本结构
即外层加了upx的壳,里面是一个混淆壳,再往里面才是citadel原始代码。脱掉UPX后的,混淆壳代码分支总览图:
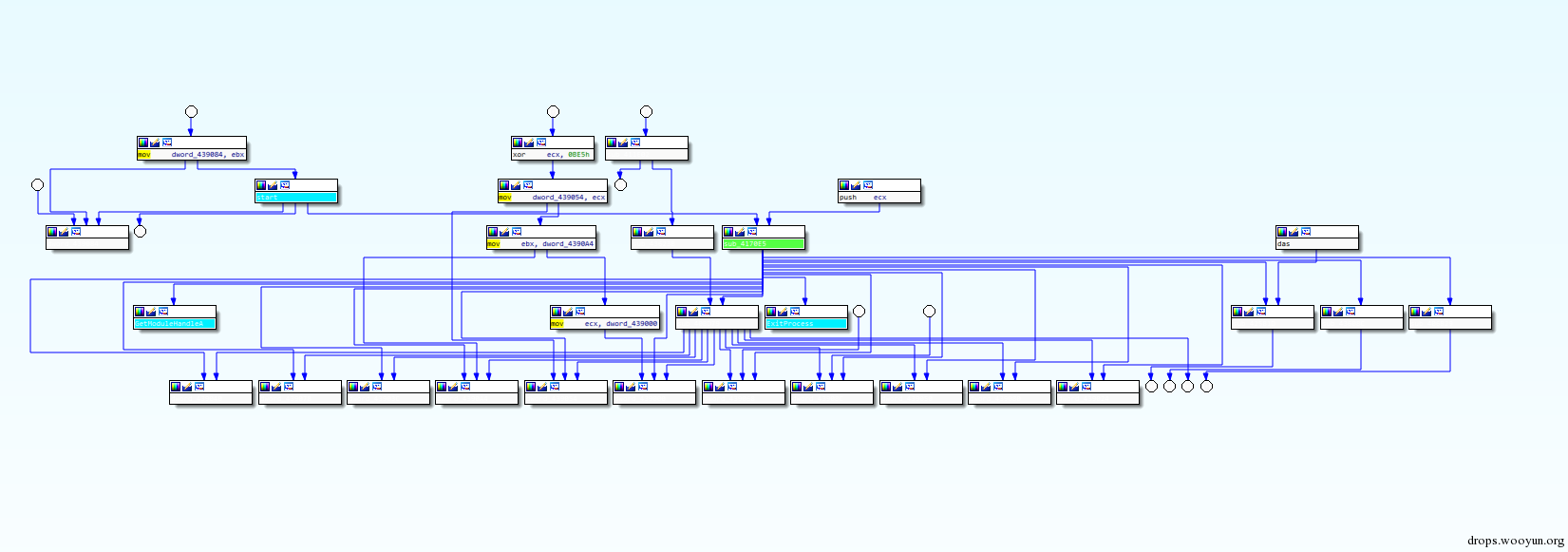
图2混淆壳代码分支总览图
对于citadel样本本身的功能与特点,本文不会提及,刚兴趣的可以自己去查资料,这里主要讲讲citadel壳的一些特点,与常见的几种混淆的手段。
下面的图为该混淆壳的混淆代码片段,其中这么一大段代码中只有红框中的指令是有用的。其他都是无效指令。很显然比一般的垃圾指令填充不知道高到哪里去了。
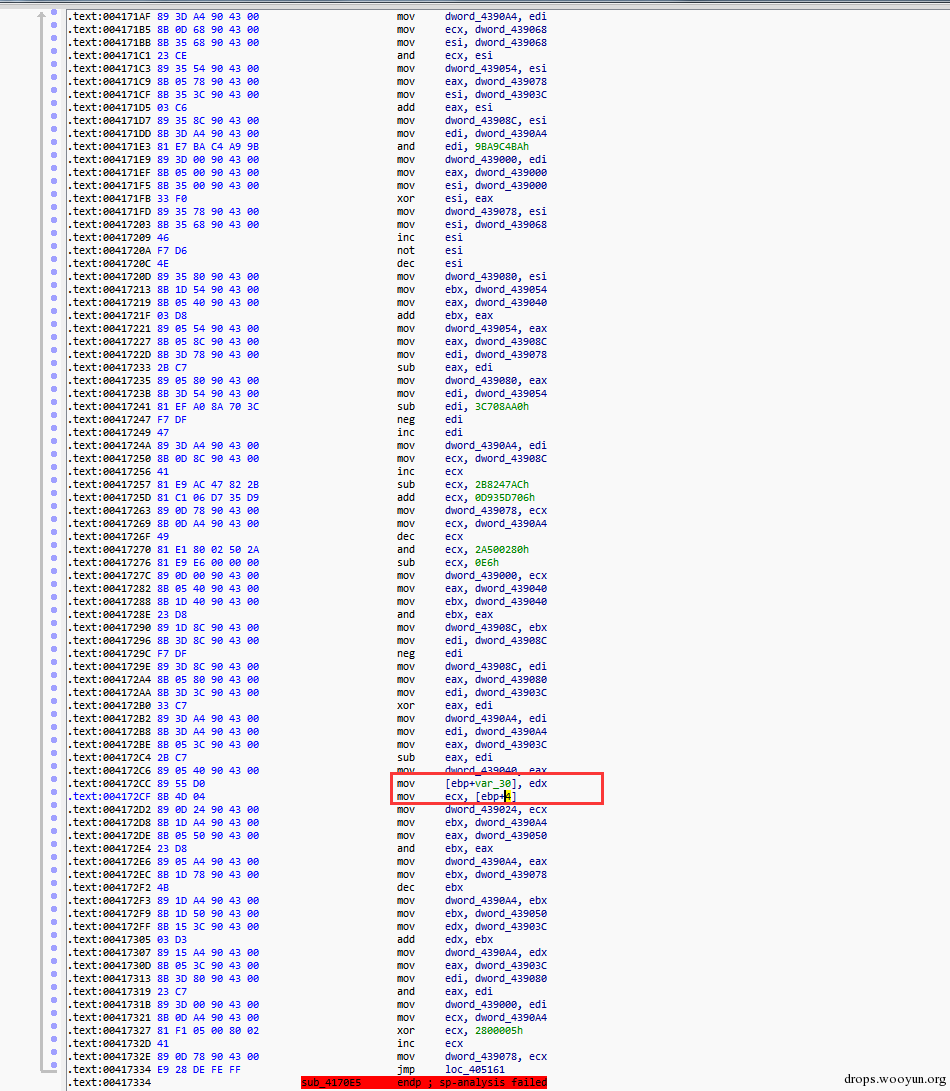
图 3,混淆片段实例
当手动脱掉upx后,运行样本后就崩溃了,然而不脱upx壳,样本是可以正常运行的。运行前后api trace 对比图:
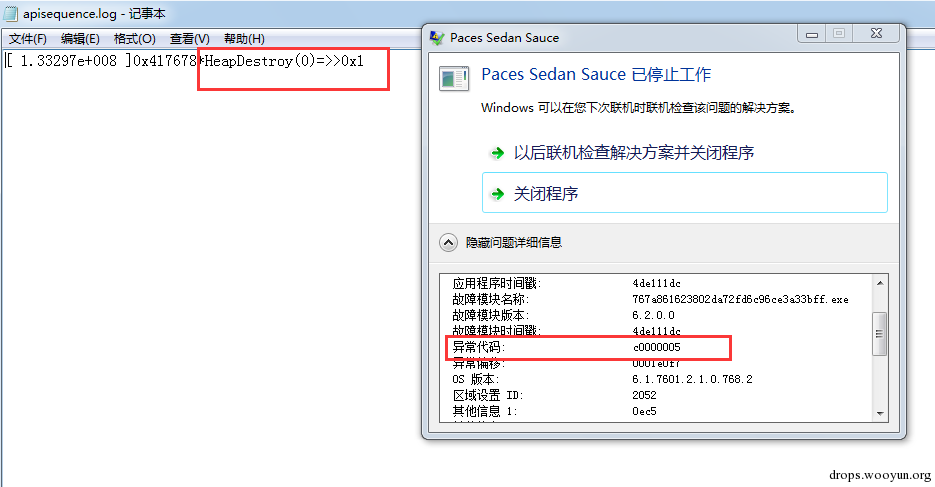
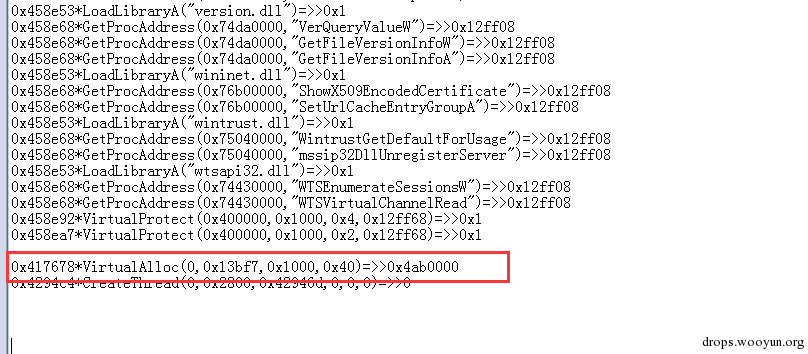
图4,api trace
其中上图是脱掉upx壳的api log,下图为没脱upx壳的api log,从图中我们可以看到在地址0x4176768地址中的调用的API名不同。很显然从这里出错了。从这个地址往上回溯,这个调用api的过程被划分为十几个代码块,然后利用JMP连接起来,其中每个代码块就只有一两条代码是有效指令:
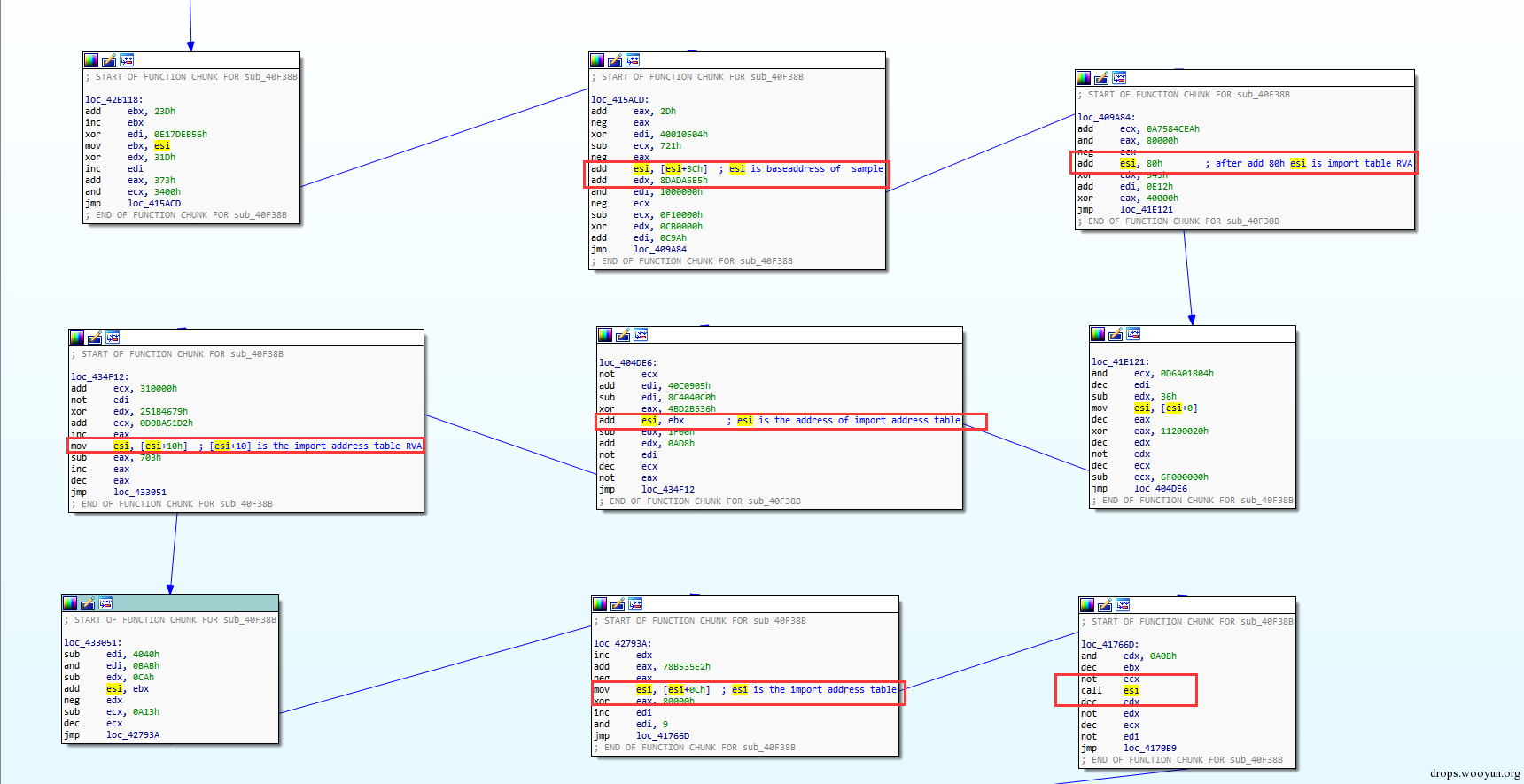
图5,获取导入表导入函数地址表第四项过程
通过上图我们发现call esi指令中esi的值由mov esi,[esi+0xch]获得,esi+0xch的值是导入函数地址表中第四项的api的地址。所以问题很可能出现在这里,即脱壳后与脱壳前导入地址表第四项api不同。

图6,没脱upx壳的导入函数地址表:

图 7,脱掉upx壳的第四项:
所以我们可以看出问题就出现在这里。即脱壳后与脱壳前导入函数地址表的不同导致了脱壳后citadel运行奔溃.从这一点可以看出这个样本在加壳的时候就是upx壳与内层混淆壳是天然一体的。

图 8,,代码执行流程
在这个样本中,各种混淆函数中,大部分的代码是操作都是在操作0x439000-0x4390a4区块的数据,其中混淆函数里面插入一两条真正有用的代码,如图1红框中的指令,然后这些混淆函数串联起来,完成对0x4390a8开始大小为0x3b70的数据的解密。如果对这种类型混淆壳不熟悉的的话很容易被这些无用的混淆指令所干扰,分析人员可能会花费大量的时间在理解这些无用的计算上面了。
如前面所说citadel大部分的混淆代码主要是操作数据读写,主要的混淆代码是由一下几种模式组合起来,形成这种长的混淆代码片段的,作者使用这几种模式:
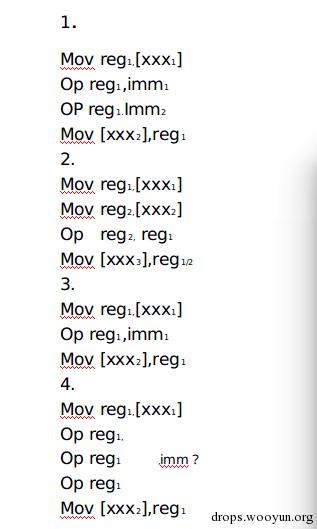
如下图所示
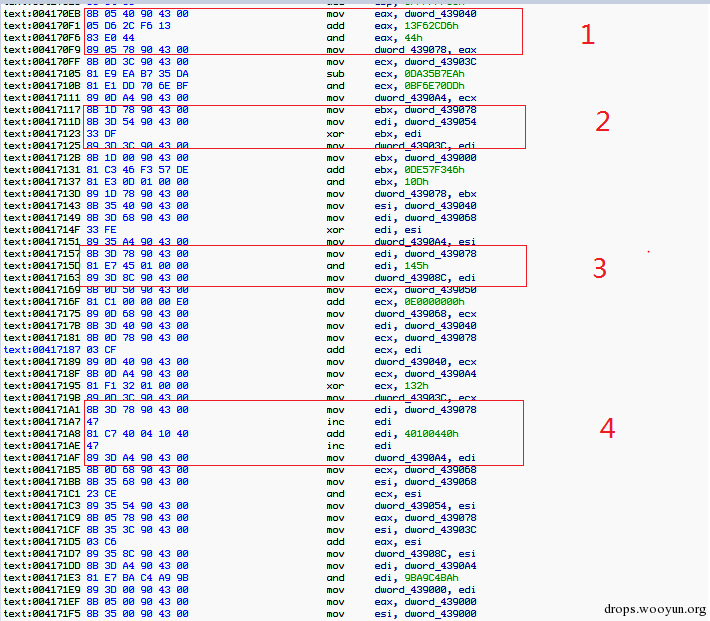
图9,混淆模式
基本上在Routine1的混淆代码中就是这种代码的随机组合形成的,然后用控制流程指令,如jmp/jz/jnz/jne/je连接起来。
需要说明的是这几种混淆方式是完全可以同时存在的。
对于编译器来说在生成代码的时候,一般情况下逻辑相关的代码块都处在相距离比较近的位置。但是对于混淆来说是故意打破这种规则的,毫无疑问这将会使分析人员花费更长的时间来分析此类样本。
即将一个函数过程分割成更多的流程。扰乱分析者对样本分析,很显然这样的过程会使分析者感到沮丧,严重拖慢了分析效率。这个在citadel中是有体现的。即在执行Routine2堆内存代码的时候:
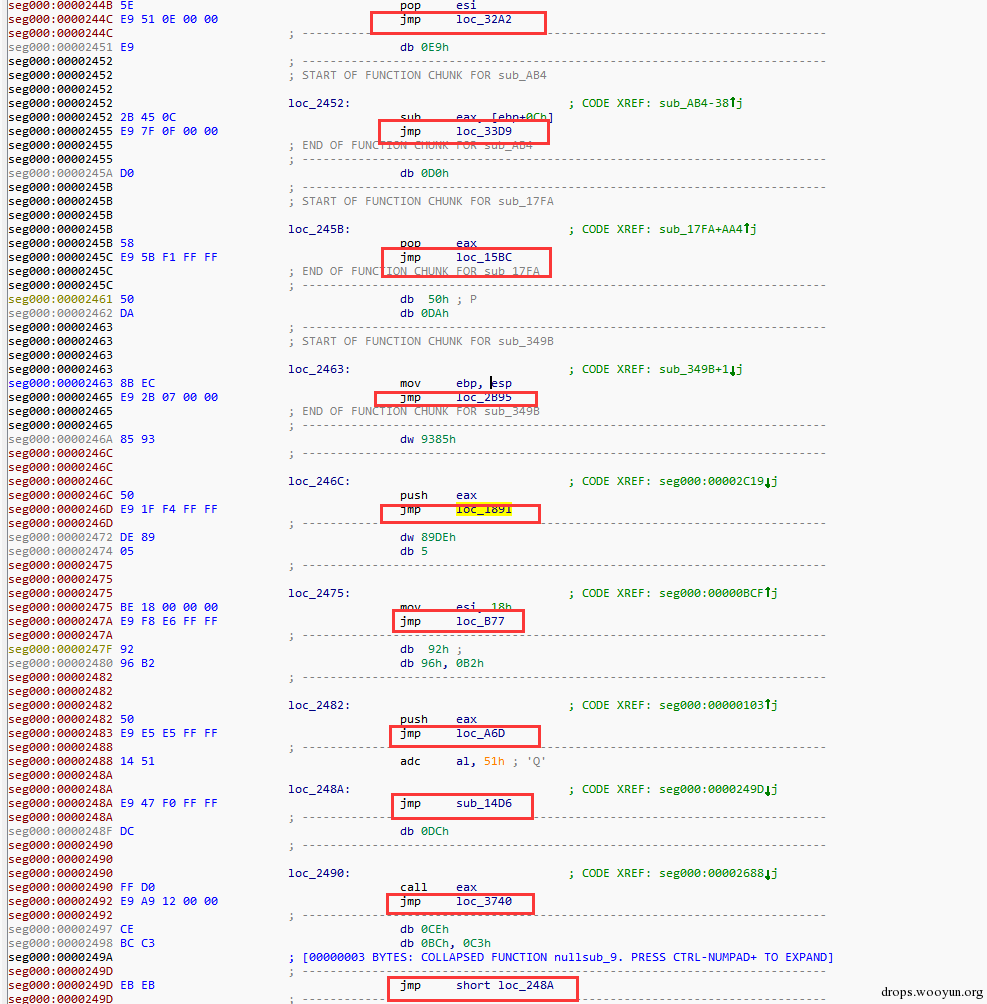
图10 代码块分割
每执行一跳指令就会jmp到另一个代码块。当然这只是一个很小的例子,其中这里面可以更加的复杂,比如添加更多的dead code blocks。
常量拆分是一个比较常用的混淆手段,主要目的是隐藏真实的代码逻辑,让分析者内心崩溃
比如:value=9*8,实际上value就是72,恶意代码编写者故意让这些常数72,在运行时由乘法指令产生。常量拆分就是一种逆向的操作,把本来可以直接获取的值,通过计算来产生的一种混淆方式。如下图:
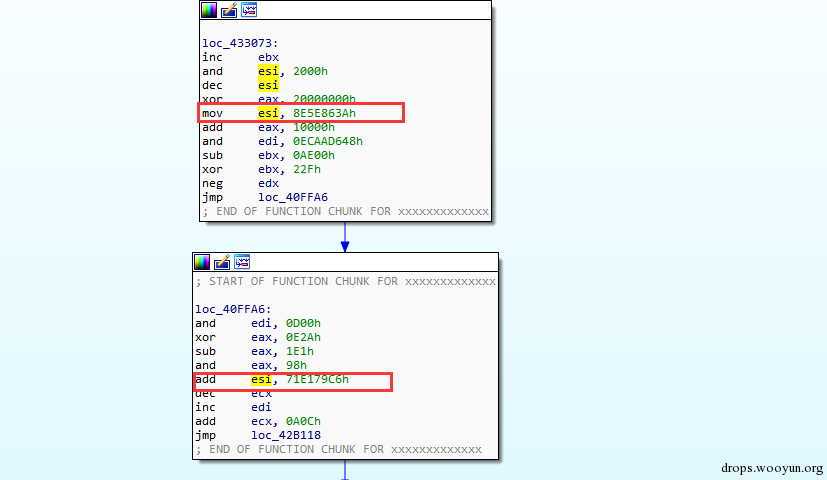
图11,常量拆分
本来直接可以mov esi,0x400000,但是却拆分成两部分而且其中添加不少无效指令
其中经过红框中的计算可以得到esi的值为0x400000.这一步的目的是获取pe文件基址。很显然恶意代码作者没有考虑地址随机化问题。
数据编码的原理就是将常量数据动态编码,然后在动态的解解码,数据编码集中体现在加密解密上。同样在citadel这个样本里我们发现有这样的过程,如下图:
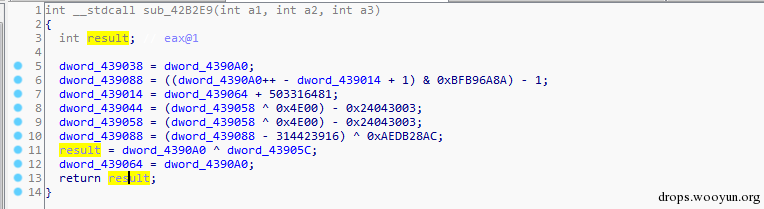
图12,数据编码
Result由 4390a0与43905c异或获取,而这两个值也是动态计算出来的。所以这样的编码如想静态的获取result会比较困难。
对于指令的替换,这个大家见得比较多。就是指令的拆分,或者合并,目的是使分析人员更加难以理解,或者拖慢分析速度。
MOV Mem,Imm
CMP/TEST Reg,Mem --> CMP/TEST Reg,Imm
Jcc @xxx Jcc @xxx
MOV Reg,Imm -> LEA Reg,[Imm]
ADD Reg,Imm -> LEA Reg,[Reg+Imm]
MOV Reg,Reg2 -> LEA Reg,[Reg2]
ADD Reg,Reg2 -> LEA Reg,[Reg+Reg2]
OP Reg,Imm -> MOV Mem,Imm TEST Reg,Imm -> MOV Mem,Reg
OP Mem,Reg Jcc @xxx AND/TEST Mem,Imm
MOV Reg,Mem Jcc @xxx
这些指令的含义很简单,这里就不介绍了。类似的这种指令替换方式变化无穷。
在去年的recon大会中《The M/o/Vfuscator-Turning 'mov' into a soul-crushing RE nightmare》议题,让我们见识到了,代码混淆的另一种方式,作者演示了所有的机器指令,除过控制流指令外,都用mov指令来实现,很显然,如果人为去理解这样的代码,是很困难的,这个可以看出作者对x86指令深入的理解,让我们大开眼界,下面我就从我的角度来说明下这个背后的原理和一些细节。先来直观的感受下,这些代码指令吧:
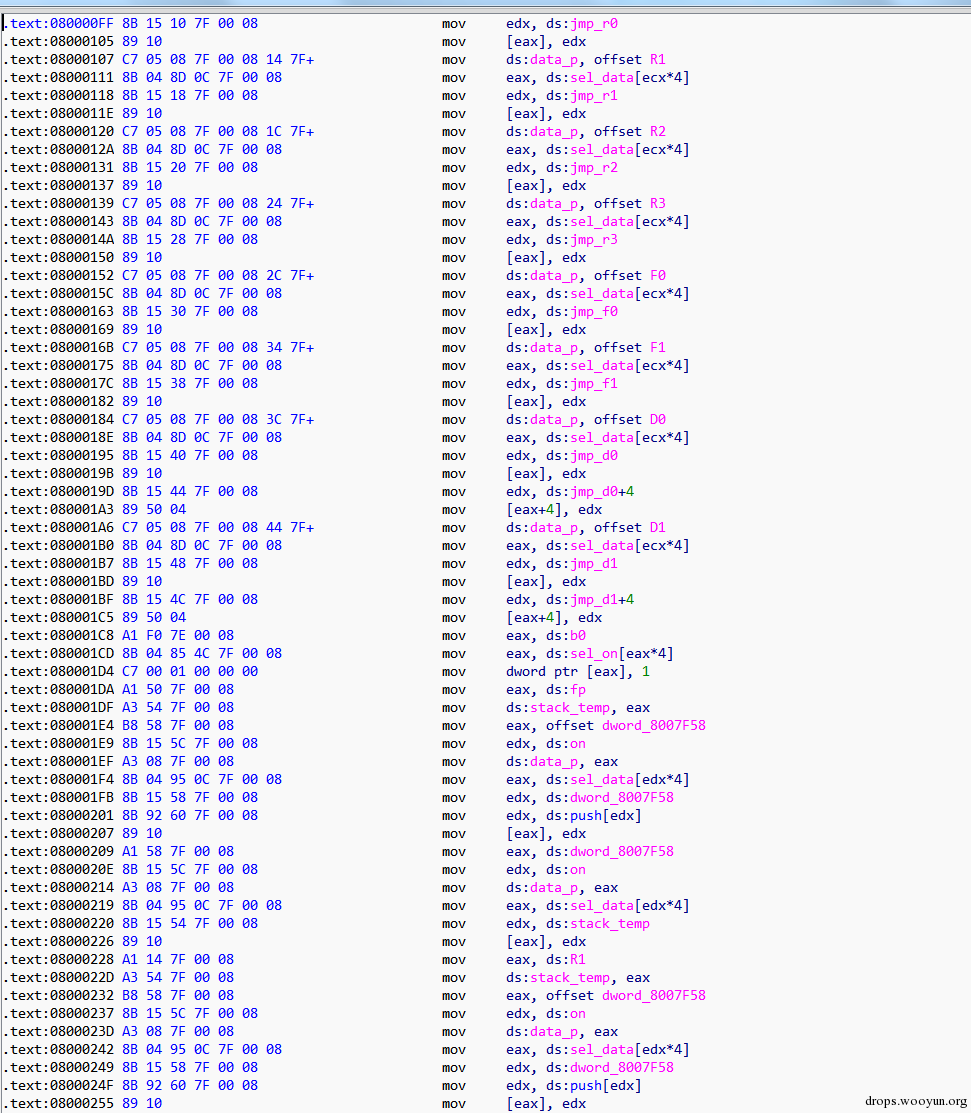
图13,mov 混淆代码
源码是这样子的:

图14,源代码
可以看出本来一个很简单的c程序代码,现在混淆的面目全非。
技术原理:
Christopher Domas 的这个议题源自Stephen Dolan的一篇paper《mov is Turing-complete》
所谓图灵完备指的就是如果一个系统的数据操作规则(比如计算机指令集,编程语言)能够模拟任意的单磁带图灵机就成称之为图灵完备。我们主要看看Christopher Domas是如何来完成mov obfuscation的。
首先解释一下为什么Chirstopher Domas为什么会选择 mov指令。
Mov指令可以用于内存读写,同时可以将立即数载入到寄存器,并且有不少寻址模式,它没有条件分支和比较的功能,因此貌似不是很显性图灵完备。在有限的时间里执行有限的数量的mov指令序列,为了图灵完备性,除过mov指令外还得再加入跳转指令,这样一来就完全符合图灵完备了。
对于mov指令来说,不能实现跳转,代码的执行流就只有一种,所以需要跳转指令来帮助实现跳转来完成真正意义上的图灵完备。
所以整体上说代码流如下:
**Start: mov … mov … mov … mov … mov … mov … jmp Start **
mov模拟其他指令伪代码:
case 1: // mov检查值是否相等:
x==y?
mov [x], 0
mov [y], 1
mov R, [x]
很显然当x==y的时候R的值就是1,否则为0。
Case2://条件分支指令
IF X == Y THEN
X=100
对于这种分支代码,设置一个Selector(相当于一个指针),一个data内存区域存放的数据是100,一个scratch 内存区,是存放的原始x的原始值,如果x的值与y的值相等的话就将selector的指向data区,如果不等就将selector指向scratch区域。

从上图我们可以总结出具体的实现原理是这样的:
#!c
int* select_x[]={&DUMMY_X , &X}
*select_x[x==y]=100
即selector就是一个包含有假的X地址(DUMMY_X)与X的真实地址的数组,如果X等于Y则select_x[x==y]指向第二个元素,并给*X赋值等于100,否则selector_x[x==y]是DUMMY_X。
模拟代码:
mov eax,[X]
mov [eax],0
mov eax,[Y]
mov [eax],4
mov eax,[X]
mov eax,[Select_x+eax]
mov [eax],100 ;X=100
在这里可以看出作者很巧妙的利用x86指令内存排布特性分别在X ,Y,所代表的内存地址放置值0,4,这刚好是DUMMY_X与X地址的偏移,这样[Select_x+eax]就指向了DUMMY_X或者X,最后赋值X或者DUMM_X,实现了上面的整个的过程。这里可以看出代码比正常的汇编指令膨胀了不少。正常汇编指令最多4条就够了,这里用到了7条,很显然现在代码不是那么容易理解了。
一些模拟指令序列:
两个值相等
%macro eq 3
mov eax, 0
mov al, [%2]
mov byte [e+eax], 0
mov byte [e+%3], 4
mov al, [e+eax]
mov [%1], al
%end macro
其中%2 %3 为要比较的两个值,%1为比较的结果。
两个值不等
%macro neq 3
mov eax, 0
mov al, [%2]
mov byte [e+eax], 4
mov byte [e+%3], 0
mov al, [e+eax]
mov [%1], al
%endmacro
neq与eq的差别就在第三条与第四条指令中,赋值的区别,
创建一个选择器
; create selector
%macro c_s 1
%1: dd 0
d_%1: dd 0
s_%1: dd d_%1, %1
%endmacro
即一个4字节的内存块,包含两个元素 %1 ,d_%1
关于循环与分支
Extend the if/else idea
On each branch
If the branch is taken
Store the target address
Turn execution “off”
If the branch is not taken
Leave execution “on”
解释下上面的意思,分支代码被触发的时候,保存目标地址代码,置位该执行为关闭状态,
如果分支代码没有被执行,置位离开执行块状态。
On each operation
If execution is on
Run the operation on real data
If execution is off
Is current address the stored branch target?
Yes?
Turn execution “on”
Run operation on real data
No?
Leave execution “off”
Run on dummy data
如果执行块开启,执行真实代码,如果执行块关闭,先判断当前地址是否存储了目标指令代码,如果是,将执行体置位为on,执行代码。如果不是,置离开执行体为off,执行dummy data中的代码。关于mov 混淆的更多的细节,可以查看去年recon的议题与相关的视频。
利用编译器进行混淆的样本不是很常见,但是这类的样本将会成为一个新的发展方向。 编译器代码混淆就是在编译器生成二进制代码的时候插入混淆代码。下面简单的介绍下一个实例。
原理就是在tcc生成机器码的时候加入混淆函数。作者patch了tcc编译器加入了一些混淆的指令:
插入混淆代码序列的过程
#!c
for (i=0; i<t; i++)
{ int q;
q=rand_reg (0, 4);
switch (q)
{
case 0: // add
rrr=genrand(); curval=curval+rrr;
o(0x81); oad(0xc0 | (0 << 3) | r, rrr); // add
break;
case 1: // sub
rrr=genrand(); curval=curval-rrr;
o(0x81); oad(0xc0 | (5 << 3) | r, rrr); // add
break;
case 2: // shl
rrr=genrand()&0x7; curval=curval<<rrr;
o(0xc1); /* shl/shr/sar $xxx, r */
o(0xe0 | r);
g(rrr);
break;
case 3: // shr
rrr=genrand()&0x7; curval=curval>>rrr;
o(0xc1); /* shl/shr/sar $xxx, r */
o(0xe8 | r);
g(rrr);
break;
case 4: // xor
rrr=genrand(); curval=curval^rrr;
o(0x81); oad(0xc0 | (6 << 3) | r, rrr); // xor
break;
};
首先随机选取了寄存器,Genrand()是产生随机数的函数,o()是产生opcode的函数,oad()是产生指令其余部分的函数。每次随机选取一个寄存器,然后对选取的寄存器产生对应的混淆指令。

对于call指令会产生这样的代码:
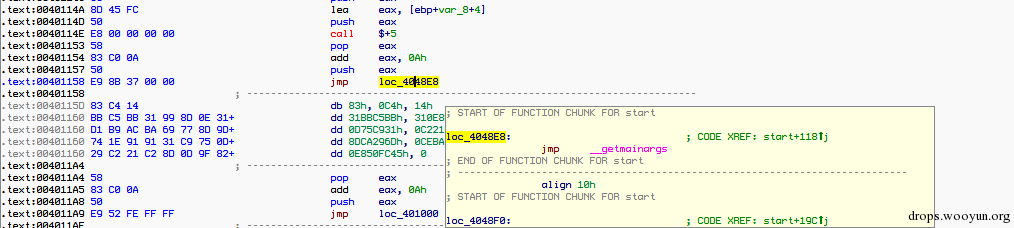
对应的代码如下:
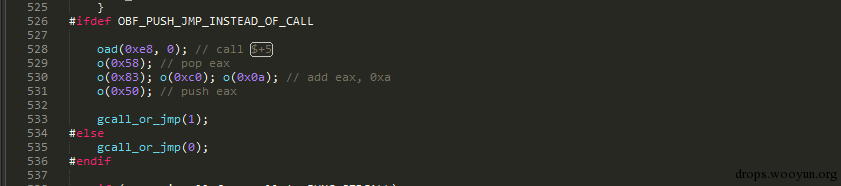
就是在原始的call 之前加入代码,最后jmp到原来的流程,然后返回继续执行下面的流程。还有很多的细节这里就不一一介绍了,如果感兴趣可以自己研究下源码。
从上面可以看出混淆技术的种类繁多,但是也是有层次的,对于海量样本的处理,反混淆流程是必须的,也是一个很重要的流程,怎么做,如何做,这将直接影响到对恶意样本的分类,数据提炼效果上,所以这是一个很有意义的话题,关于如何反混淆,将会在后续的文章谈到。
参考文献: